Data Structure 9
Nicholas Kristianus Putra
2301909775
CB01-CL
Ferdinand Ariandy Luwinda D4522
Henry Chong D4460
Rangkuman Gabungan
Circular Singly Linked List
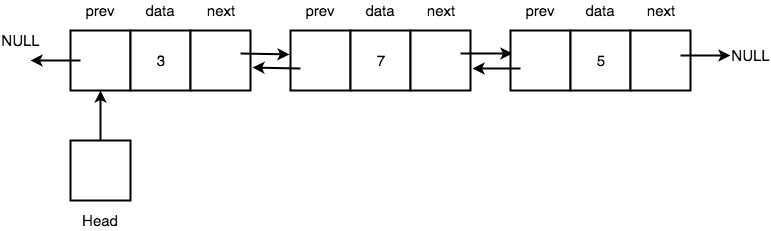


- Masing-masing node hanya punya satu pointer, yaitu pointer yang menunjuk ke alamat node berikutnya (next)
- Pointer pada node terakhir menunjuk kembali kepada alamat dari node pertama, maka tidak ada yang menunjuk pada nilai NULL dalam linked list jenis yang ini
Doubly Linked List
- Masing-masing node mempunyai 2 pointer, pointer pertama berfungsi untuk menunjuk alamat node sebelumnya, pointer yang kedua berfungsi untuk menunjuk ke alamat pointer berikutnya
- Pointer pada node pertama yang berfungsi untuk menunjuk alamat node sebelumnya menunjuk pada NULL
- Pointer pada node terakhir yang berfungsi untuk menunjuk alamat node berikutnya menunjuk pada NULL
Circular Doubly Linked List
- Cara kerjanya sangat mirip dengan "Circular Singly Linked List", tetapi pada linked list jenis yang ini masing-masing node mempunyai 2 pointer, yaitu pointer yang menunjuk kepada node berikutnya dan pointer yang menunjuk pada node sebelumnya
Refrensi
Rangkuman Pertemuan 6
Gw belajar beberapa hal dari kelas
besar tadi pagi. Yang pertama, gua diajarin sama Pak Ferdinand logic
dari codingan linked list. Pak Ferdinand jelasin dengan step by step dan
langkah-langkah dari pembuatan codingan Singly Linked List.
Mulai dari logic headnya biar bisa stay di depan dan ga gerak-gerak,
current yang harus bisa gerak sesuai dengan berapa kali kita next
valuenya, dan gimana caranya tail bisa didorong sampe ke data yang
terakhir dan stay di sana.
Selain itu, gua juga belajar kalo dalam codingan Linked List, mungkin banget buat kami (mahasiswa yang belum berpengalaman dalam coding Linked List)
buat salah logic saat coding dan ga menyadarinya sampe beberapa waktu.
Misalnya, salah mendefinisikan head->nextnya atau apapun itu mungkin
ga langsung membuat programnya crash dan gabisa jalan, tapi pas kita
coba masukin semua value datanya pasti ada yang salah. Maka dari itu gua
juga belajar bahwa kita harus bukan dengerin penjelasan Pak Ferdinand
kayak yang tadi pagi kita lakuin, tapi juga coba sendiri di luar kelas
dan diulang-ulang agar logicnya lebih ngerti lagi dan udah jadi terbiasa
dengan kesalahan-kesalahan dalam ngoding Linked List nantinya.
Gw juga belajar logicnya "pop" (menghapus value dari data) dalam Linked List dan
kesalahan-kesalahan yang seringkali dilakuin oleh mahasiswa dalam
ngoding "pop". Yang banyak banget dibahas juga tadi itu, seringkali kita
udah berhasil merangkai codingan suatu function, tapi kita
seringkali lupa kalo codingan kita biasanya hanya berlaku di saat
kondisi datanya masih lebih dari satu. Maka dari itu, kita juga gaboleh
lupa untuk nambahin kondisi jika datanya udah tinggal 1 atau jika
datanya udah dipaling ujung (intinya kondisi yang beda sendiri dari yang
lain dan cara penyelsaiannya juga harus dibedain dari "kondisi normal"
biasanya).
Gw juga belajar kalo kita bisa ngeprint semua value dari data yang ada dengan gausah ribet ngeprint satu-satu. Kita bisa dapetin pola (seperti kalo dalam kasus yang tadi itu curr->next), abis itu kita tinggal pake looping untuk ngeprint smua value dari datanya sampe datanya habis.
Dan yang terakhir, gw juga diajarin sekilas logic dari codingan Doubly Linked List dan logic dari "previous". Keunggulan dari Doubly Linked List itu salah satunya adalah saat kita mau ngebuat fungsi "pop" yang bisa dilakuin jauh lebih gampang karena kita punya tangan untuk "previous"nya. Tapi kelemahannya ya kita jadi lebih ribet karna harus ngurus 2 tangan. Pak Ferdinand juga bilang kalo dalam kasus-kasus tertentu terkadang ada baiknya kita punya lebih dari 1 current. Fungsinya adalah tentunya mempercepat pencarian data kalo datanya emang udah semakin banyak. Bahkan kita bisa buat tangan sebanyak-banyaknya yang kita mau even sampe 8 tangan. Tapi, dalam kebanyakan kasus 4 tangan udah cukup banget buat menyelsaikan permintaan yang kita minta ke komputer kita.
Gw juga belajar kalo kita bisa ngeprint semua value dari data yang ada dengan gausah ribet ngeprint satu-satu. Kita bisa dapetin pola (seperti kalo dalam kasus yang tadi itu curr->next), abis itu kita tinggal pake looping untuk ngeprint smua value dari datanya sampe datanya habis.
Dan yang terakhir, gw juga diajarin sekilas logic dari codingan Doubly Linked List dan logic dari "previous". Keunggulan dari Doubly Linked List itu salah satunya adalah saat kita mau ngebuat fungsi "pop" yang bisa dilakuin jauh lebih gampang karena kita punya tangan untuk "previous"nya. Tapi kelemahannya ya kita jadi lebih ribet karna harus ngurus 2 tangan. Pak Ferdinand juga bilang kalo dalam kasus-kasus tertentu terkadang ada baiknya kita punya lebih dari 1 current. Fungsinya adalah tentunya mempercepat pencarian data kalo datanya emang udah semakin banyak. Bahkan kita bisa buat tangan sebanyak-banyaknya yang kita mau even sampe 8 tangan. Tapi, dalam kebanyakan kasus 4 tangan udah cukup banget buat menyelsaikan permintaan yang kita minta ke komputer kita.
Hashing Table
Gw nonton beberapa video youtube tentang hashing table di data structure dan gw belajar beberapa hal. Yang pertama, gw belajar secara kasar apa itu pengertian dari hashing table. Yang gw dapet, hashing table itu mirip dengan kalo kita mau cari seseorang secara spesifik di contact hp kita. Jadi di videonya, dia gambarin hashing table itu kayak array dengan index-index seperti biasanya. Misalnya, kita mau masukin nomor seseorang. Kita tinggal masukin dengan fungsi "hash" dan masukkin kode yang menunjuk kepada nomor orang tersebut. Misalnya itu nomornya si Budi, brati yang kita masukkin ke dalem fungsi hashing tablenya adalah "Budi". Nanti, hashing tablenya bakal
ngeluarin index (yang berarti, di index berapa si nomor teleponnya Budi
disimpen), misalnya nomor telepon Budi disimpen di index 0. Dan kita
bukan cuman bisa simpen 1 value doang..kita bisa simpen banyak value
dengan kode-kode yang berbeda untuk menunjuk ke value yang beda-beda
juga.
Misalnya, abis gw masukkin
value yang pertama (nomor telepon Budi), gw mo masukin value yang kedua,
yaitu nomor teleponnya si "Charles". Gw bisa lansung pake fungsi hash yang tadi dan masukkin kode gw yg merujuk ke valuenya (nomor telepon di Charles). Dan si hashnya juga
bakal nunjukin index berapa si value Charles ini disimpen. Selanjutnya
gw mau masukkin nomor teleponnya Quincy misalnya, gw juga tinggal
panggil fungsi hash yang tadi dan langsung masukkin kode "Quincy" (yang merujuk kepada value nomor teleponnya si Quincy).
Nah tapi, akan ada saat di saat kita mau masukkin value lagi (misalnya Joni), si fungsi hashnya malah ngeluarin index yang udah pernah keluar, misalnya index 0. Nah untuk menanggulangi masalah ini, dalam hashing table, kita
ga ngebuang value dari Budi ataupun Joni, melainkan dia ngebuat semacem
"linked list di dalam array". Mungkin kalo liat gambar di bawah jadi
lebih kebayang..
Dan
setiap kali kita mau nyari nomor telepon dari si Joni, kita ga perlu
cari satu-satu value apa aja yang udah pernah kita masukkin ke dalem hashing table ini, melainkan kita tinggal masukkin kata kuncinya, yaitu "Joni"..dan fungsi hashnya bakal
ngeluarin di index berapa si value Joni itu disimpen. Dalam konteks
ini, value (nomor telepon si Joni) disimpen di index ke 0 (bebarengan
dengan value si Budi). Nah, setelah kita udah tau kita harus mulai
pencarian ini dari index ke berapa, kita baru deh mulai cari dengan
caranya kita nyari data di "linked list" seperti biasanya. Kalo sekarang
gw balikin lagi ke metode pencarian nomor telepon seseorang dalama
aplikasi contact di hp kita masing-masing udah kebayang kan maksudnya
kayak apa.
Gw juga nonton apa hubungan hashing table dalam block chain. Dan dalam block chain ini bahkan lebih revolusioner lagi menurut gw. Di videonya gw belajar bahwa bahkan hashing table itu sendiri punya syarat-syarat penting kalo mau diimplementasikan ke dalam block chain (ada 5 syarat). Pertama, perubahan sedikit aja terhadap hashnya/keynya, data yang berubah juga harus signifikan perubahannya. Kedua, hashing dalam block chain setiap kali kita input key yang sama, outputnya juga harus sama persis. Ketiga, proses penyocokan input dengan outputnya juga harus berjalan dengan cepat agar prosesnya efisien. Keempat, infeasible yang berarti kita bakal bisa ngebuka suatu kode di saat kita bisa cocokin semua inputnya dengan outputnya. Kita emang bisa cobain satu-satu, tapi dalam data yang banyak banget, bisa dibilang mau kita cobain setiap detik pun sampe tua ga akan pernah kelar. Dan terakhir yang kelima, setiap output/value harus punya input/key yang unik dan berbeda dari yang lain.


Gw juga nonton apa hubungan hashing table dalam block chain. Dan dalam block chain ini bahkan lebih revolusioner lagi menurut gw. Di videonya gw belajar bahwa bahkan hashing table itu sendiri punya syarat-syarat penting kalo mau diimplementasikan ke dalam block chain (ada 5 syarat). Pertama, perubahan sedikit aja terhadap hashnya/keynya, data yang berubah juga harus signifikan perubahannya. Kedua, hashing dalam block chain setiap kali kita input key yang sama, outputnya juga harus sama persis. Ketiga, proses penyocokan input dengan outputnya juga harus berjalan dengan cepat agar prosesnya efisien. Keempat, infeasible yang berarti kita bakal bisa ngebuka suatu kode di saat kita bisa cocokin semua inputnya dengan outputnya. Kita emang bisa cobain satu-satu, tapi dalam data yang banyak banget, bisa dibilang mau kita cobain setiap detik pun sampe tua ga akan pernah kelar. Dan terakhir yang kelima, setiap output/value harus punya input/key yang unik dan berbeda dari yang lain.
Rangkuman Binary Tree
Tugas Rangkuman 004
Gw belajar apa itu "Binary Tree" dalam
Data Structure itu dari Youtube. Sebelumnya, gua cuman pernah tau
istilah "Binary Tree" ini dalam mata kuliah "Matematika Diskrit" pas gw
masih semester 1 kemaren. Mungkin, di semester 1 yang lalu, itu juga
tujuannya gw diajarin konsep "Binary Tree" ini untuk membangun pondasi
konsep gw tentang Binary Tree di semester yang akan datang seperti
sekarang.
Nah dari Youtube, gw
belajar atau diingetin lagi apa itu Binary Tree. Yang gw dapet, Binary
Tree itu adalah konsep Tree yang mempunyai akar/root pastinya. Tapi,
yang membedakan dia dari Tree biasa itu adalah banyak anaknya/cabangnya.
Kalau dalam Binary Tree, kita cuman bisa punya anak sebanyak 0-2
anak/cabang.
Nah, Binary Tree ini
pun masih ada jenis-jenisnya lagi. Yang pertama itu, Strict Binary
Tree, di mana kita cuman boleh punya anak antara 0 atau 2. Jadi, kita
gaboleh cuman punya 1 anak, apalagi 3, 4, 5, dst.
Nah,
jenis Binary Tree yang ke-2 itu namanya Complete Binary Tree yang
justru punya aturan lebih strik lagi dari yang sebelumnya. Aturannya
adalah, kita harus punya anak sampe level yang sejajar. Maksudnya itu,
dalam "dunia" Tree ini kita bakal kenal sama yang namanya level-levelan.
Kalau misalnya root/akar itu kita anggap adalah level 0, maka anak
pertama dari root ini kita sebut levelnya menjadi level 1. Begitu pula
seterusnya. Nah jadi kalau misalnya di antara cabang-cabang kita ada
yang punya anak sampe dengan level 3, maka semuanya juga harus ngikutin
punya anak sampe level 3 juga. Mungkin agak susah kalo dibayangin tanpa
gambar. Makanya nih gw kasih gambarannya biar lebih kebayang.
Nah kita bisa liat dari gambar di atas, perbedaannya Binary Tree yang "complete" sama yang "gak complete".
Dan
jenis Binary Tree yang terakhir itu namanya "Perfect Binary Tree".
Kenapa dinamain perfect, karena dia bentukannya harus kayak gambar di
bawah ini.
Nah, kalo udah ngerti konsepnya dalam matematika, kita tinggal terapin ke dalam codingannya.
deklarasiin tree dalam bahasa C bisa dengan struct kayak gini:
struct node
{
int data;
node* left;
node* right;
};
Kenapa
harus ada left dan right? Karena masing-masing node dalam tree ini bisa
punya 0-2 anak. Kalo seandainya punya 0 anak, makan nilai pointer dari
left dan rightnya = NULL.
Tapi
kita juga bisa deklarasiin Binary Tree ini bukan hanya dengan struct
aja, bisa juga dengan array. Tapi, ini cuman berlaku kalo kita mau bikin
"Perfect Binary Tree" aja. Kita bisa mulai dari root sebagai index 0,
anak left dari rootnya sebagai index 1, anak kanan dari rootnya sebagai
index 2, dan seterusnya. Setelah itu, kita bisa pake logic untuk node
pada index i, index anak kirinya = 2i + 1 dan index anak kanannya = 2i +
2
Kenapa sih kita harus belajar AVL Tree? Kan kita udah bisa bikin coding BST..
Jawabannya karena di kasus-kasus tertentu, BST bisa aja ga seimbang. Misalnya kalau kita insert angka dari 1 sampe 10, BST-nya bakalan berat di kanan. Akibatnya yang menjadi salah satu dari tujuan kita bikin BST (yaitu buat mempercepat pencarian menjadi 2 log n) itu ga tercapai. Kalo misalnya BST kita jadinya cuman garis lurus doang, berarti kalo kita mau cari satu data, tetep aja harus travel sebanyak n data. Nah, si AVL ini membuat pencarian tree kita jadinya lebih efektif. Meskipun memang kecepatan carinya belum persis selalu = 2 log n, tapi jauh lebih mendekati 2 log n dibanding sebanyak n.
Nah, jadi dalam AVL, cara kita masukin data sama persis kayak di BST. Yaitu, kalo data baru yang kita masukin lebih kecil, maka bakal ke kiri, kalo lebih besar, maka bakal ke kanan. Yang ngebedain adalah dalam AVL, perbedaan tinggi dalam tree kita itu HARUS lebih kecil dari 2 (jadi perbedaan yang masih boleh itu cuman 0 atau 1).
Gimana sih caranya kita bikin tree ini bedanya ga sampe 2? Caranya ada 2, yaitu single rotate dan double rotate. Pertama kita bakal bahas single rotate dulu karna lebih simpel.

Nah kita pake gambar aja biar lebih jelas. Hal pertama yang harus kita cari tau itu, di mana sih ga seimbangnya tree ini. Kalo kita liat gambar di atas, yang ga seimbang itu di '3' karena masuknya data '5'. Trus tahap kedua adalah, cari tau ini pake single rotate atau double rotate. Cara nentuinnya gimana sih? Kalo garisnya lurus (dari angka 3, 4, dan 5 itu kan lurus ke kanan), maka kita cuman perlu single rotate.
Bayangin aja pas kita ngerotate itu kayak katrol, kalo kita tarik tali katrolnya, otomatis angka 3 bakal turun dan angka 4 bakal naik kan kayak gambar di atas. Nah single rotate itu cuman kyk gitu aja. Tapi setelah kita ngerotate kita selalu harus cek penempatan datanya udah bener belom. Di gambar di atas, 3 jadi anak kirinya 4 dan 5 jadi anak kanannya 4 which is udah sesuai dengan aturan BST.
Sekarang kita bahas double rotation..

Nah, kita juga pake gambar biar lebih jelas. Double rotate itu dipake kalo kita nemuin tree yang ga stabil itu bengkok. Jadi pertama kan kita harus cari tau tree mana yang ga stabil. Dalam gambar ini, itu tree 6 (karena anak kirinya 1 dan anak kanannya 3, maka perbedaan levelnya 2 which is ga boleh). Tapi kalo kita lihat 6, 15, dan 7 itu juga ga membentuk 1 garis lurus (alias bengkok). Makanya kita harus pake double rotate. Pertama kita tarik dulu 15 dan 7 biar 7-nya di atas dan 15 di bawah. Nah sekarang kan (6, 7, dan 15) udah jadi dalam 1 garis nih. Kita tinggal pake single rotate deh. Tarik 7 agar naik ke atas, dengan begitu 6-nya otomatis turun ke bawah. Trus terakhir kita juga cek lagi apakah tree yang barusan kita rotate itu udah sesuai dengan aturan BST. Dalam gambar di atas, treenya udah sesuai dengan aturan BST. Maka double rotation kita udah selsai.
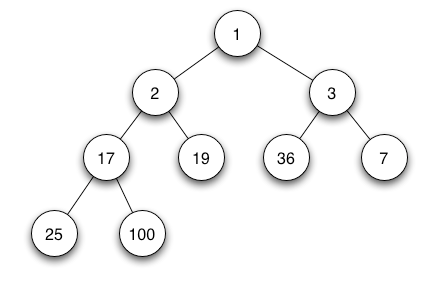
Nah ini yang dimaksud dengan ortunya slalu lebih kecil dari anak-anaknya. Jadi pas insert, rootnya masuk, kalo pada insert kedua anaknya lebih kecil dari ortunya, anak dan ortu akan diswap supaya memenuhi aturan dari min heap.
Kalo deletion, misalnya kita delete angka 1. Data terakhir yang di input akan menggantikan si satu ini, misalnya yang terakhir kali kita input itu angka 100. Maka 100 bakalan jadi rootnya. Tapi kan 100 ga lebih kecil dari anak-anaknya. Nah makanya setelah kita ganti akarnya jadi 100, kita harus bandingin ulang satu per satu. pertama kita bandingin 100, 2, dan 3. Karena 100 lebih besar dari keduanya maka 100 harus diswap, dan yang akan naik ke atas adalah nilai yang lebih kecil yaitu 2. Terus kita bandingin 100, 17, dan 19. 17 akan naik dan 100 akan turun. Bandingin 100 dan 25. 25 naik, 100 turun. Selesai deh deletionnya.

Nah kayak kita liat gambar di atas, ortunya selalu lebih gede dari anaknya. Kalo insertion ya sama aja kayak min heap cuman kebalikannya jadi data pertama masuk. Kalo data selanjutnya lebih besar dari ortunya, bakalan diswap.
Deletionnya juga kebalikan dari min heap. Jadi kalo kita apus 100, data terakhir yang di input bakal gantiin posisi 100, misalnya 7. 7 bakal naik ke yang paling atas. Terus bakal bandingin dengan anak-anaknya. Karena 7 lebih kecil dari 19 dan 36, maka bakal diswap, tapi yang naik itu nilai yang paling besar. Dalam perbandingan 7, 19, dan 36 yang paling besar adalah 36, maka 7 kita swap dengan 36. Selanjutnya kita bandingin 7, 25. dan 1. Karena 7 lebih kecil dari 25 tapi ga lebih gede dari 1, maka kita akan swap 25 dengan 7. Deletion selesai.
Video Confrence 1
AVL Tree (Adelson-Velskii and Landis Tree)
Hari ini gw belajar dari video confrence Binus tentang AVL Tree. Simpelnya, AVL tree itu cuman lanjutan dari Binary Search Tree (BST) ato bisa juga kita bilang sebagai "uprade"an dari BST.Kenapa sih kita harus belajar AVL Tree? Kan kita udah bisa bikin coding BST..
Jawabannya karena di kasus-kasus tertentu, BST bisa aja ga seimbang. Misalnya kalau kita insert angka dari 1 sampe 10, BST-nya bakalan berat di kanan. Akibatnya yang menjadi salah satu dari tujuan kita bikin BST (yaitu buat mempercepat pencarian menjadi 2 log n) itu ga tercapai. Kalo misalnya BST kita jadinya cuman garis lurus doang, berarti kalo kita mau cari satu data, tetep aja harus travel sebanyak n data. Nah, si AVL ini membuat pencarian tree kita jadinya lebih efektif. Meskipun memang kecepatan carinya belum persis selalu = 2 log n, tapi jauh lebih mendekati 2 log n dibanding sebanyak n.
Nah, jadi dalam AVL, cara kita masukin data sama persis kayak di BST. Yaitu, kalo data baru yang kita masukin lebih kecil, maka bakal ke kiri, kalo lebih besar, maka bakal ke kanan. Yang ngebedain adalah dalam AVL, perbedaan tinggi dalam tree kita itu HARUS lebih kecil dari 2 (jadi perbedaan yang masih boleh itu cuman 0 atau 1).
Gimana sih caranya kita bikin tree ini bedanya ga sampe 2? Caranya ada 2, yaitu single rotate dan double rotate. Pertama kita bakal bahas single rotate dulu karna lebih simpel.
Nah kita pake gambar aja biar lebih jelas. Hal pertama yang harus kita cari tau itu, di mana sih ga seimbangnya tree ini. Kalo kita liat gambar di atas, yang ga seimbang itu di '3' karena masuknya data '5'. Trus tahap kedua adalah, cari tau ini pake single rotate atau double rotate. Cara nentuinnya gimana sih? Kalo garisnya lurus (dari angka 3, 4, dan 5 itu kan lurus ke kanan), maka kita cuman perlu single rotate.
Bayangin aja pas kita ngerotate itu kayak katrol, kalo kita tarik tali katrolnya, otomatis angka 3 bakal turun dan angka 4 bakal naik kan kayak gambar di atas. Nah single rotate itu cuman kyk gitu aja. Tapi setelah kita ngerotate kita selalu harus cek penempatan datanya udah bener belom. Di gambar di atas, 3 jadi anak kirinya 4 dan 5 jadi anak kanannya 4 which is udah sesuai dengan aturan BST.
Sekarang kita bahas double rotation..
Nah, kita juga pake gambar biar lebih jelas. Double rotate itu dipake kalo kita nemuin tree yang ga stabil itu bengkok. Jadi pertama kan kita harus cari tau tree mana yang ga stabil. Dalam gambar ini, itu tree 6 (karena anak kirinya 1 dan anak kanannya 3, maka perbedaan levelnya 2 which is ga boleh). Tapi kalo kita lihat 6, 15, dan 7 itu juga ga membentuk 1 garis lurus (alias bengkok). Makanya kita harus pake double rotate. Pertama kita tarik dulu 15 dan 7 biar 7-nya di atas dan 15 di bawah. Nah sekarang kan (6, 7, dan 15) udah jadi dalam 1 garis nih. Kita tinggal pake single rotate deh. Tarik 7 agar naik ke atas, dengan begitu 6-nya otomatis turun ke bawah. Trus terakhir kita juga cek lagi apakah tree yang barusan kita rotate itu udah sesuai dengan aturan BST. Dalam gambar di atas, treenya udah sesuai dengan aturan BST. Maka double rotation kita udah selsai.
Heaps
Min Heaps
Gw belajar kalo heaps itu juga adalah salah satu jenis tree yang punya aturannya sendiri. Dalam min heaps, aturannya adalah ortunya harus punya nilai yang lebih kecil dari anaknya. Biar lebih kebayang yang gw maksud, gw langsung pake gambar aja yaNah ini yang dimaksud dengan ortunya slalu lebih kecil dari anak-anaknya. Jadi pas insert, rootnya masuk, kalo pada insert kedua anaknya lebih kecil dari ortunya, anak dan ortu akan diswap supaya memenuhi aturan dari min heap.
Kalo deletion, misalnya kita delete angka 1. Data terakhir yang di input akan menggantikan si satu ini, misalnya yang terakhir kali kita input itu angka 100. Maka 100 bakalan jadi rootnya. Tapi kan 100 ga lebih kecil dari anak-anaknya. Nah makanya setelah kita ganti akarnya jadi 100, kita harus bandingin ulang satu per satu. pertama kita bandingin 100, 2, dan 3. Karena 100 lebih besar dari keduanya maka 100 harus diswap, dan yang akan naik ke atas adalah nilai yang lebih kecil yaitu 2. Terus kita bandingin 100, 17, dan 19. 17 akan naik dan 100 akan turun. Bandingin 100 dan 25. 25 naik, 100 turun. Selesai deh deletionnya.
Max Heaps
Max heaps itu adalah kebalikan dari min heaps. Kalo dalam min heaps ortunya lebih kecil dari anak, dalam max heaps, ortunya harus lebih gede dari anaknya.Nah kayak kita liat gambar di atas, ortunya selalu lebih gede dari anaknya. Kalo insertion ya sama aja kayak min heap cuman kebalikannya jadi data pertama masuk. Kalo data selanjutnya lebih besar dari ortunya, bakalan diswap.
Deletionnya juga kebalikan dari min heap. Jadi kalo kita apus 100, data terakhir yang di input bakal gantiin posisi 100, misalnya 7. 7 bakal naik ke yang paling atas. Terus bakal bandingin dengan anak-anaknya. Karena 7 lebih kecil dari 19 dan 36, maka bakal diswap, tapi yang naik itu nilai yang paling besar. Dalam perbandingan 7, 19, dan 36 yang paling besar adalah 36, maka 7 kita swap dengan 36. Selanjutnya kita bandingin 7, 25. dan 1. Karena 7 lebih kecil dari 25 tapi ga lebih gede dari 1, maka kita akan swap 25 dengan 7. Deletion selesai.
Comments
Post a Comment